What is ELT and how is it different from traditional ETL tools
What is ELT and how is it different from traditional ETL tools
Differences between traditional ETL platforms and new age ELTs
ELT vs ETL
A data warehouse has been a critical part of the reporting and analytics infrastructure at companies for many decades. However, owning and operating a data warehouse has always been an expensive proposition, something that was out of the reach for most companies. With the rise of cloud data warehouses, it has become achievable for any company, small, medium, or large to own and operate a data warehouse.
Daton attempts to make building and operating a data warehouse a reality for every business.
Most development teams focused on building data warehouses may already be familiar with ETL as that term has been, and still is, central to building data warehouses.
ETL stands for Extract, Transform, and Load, a process that has been in place since the dawn of data warehousing.
- Extract process pull data from various source systems like - databases, SaaS applications, eCommerce platforms and more.
- Transform functions apply some level of transformation like aggregates, filters etc to the extracted data.
- Load jobs loads the transformed data into the desired destination.
Typically, ETL solutions rely of powerful middleware to perform transformations. This middleware layer adds a higher degree of cost to the entire application and typically these costs are passed on to the customer. Daton approaches this problem differently.
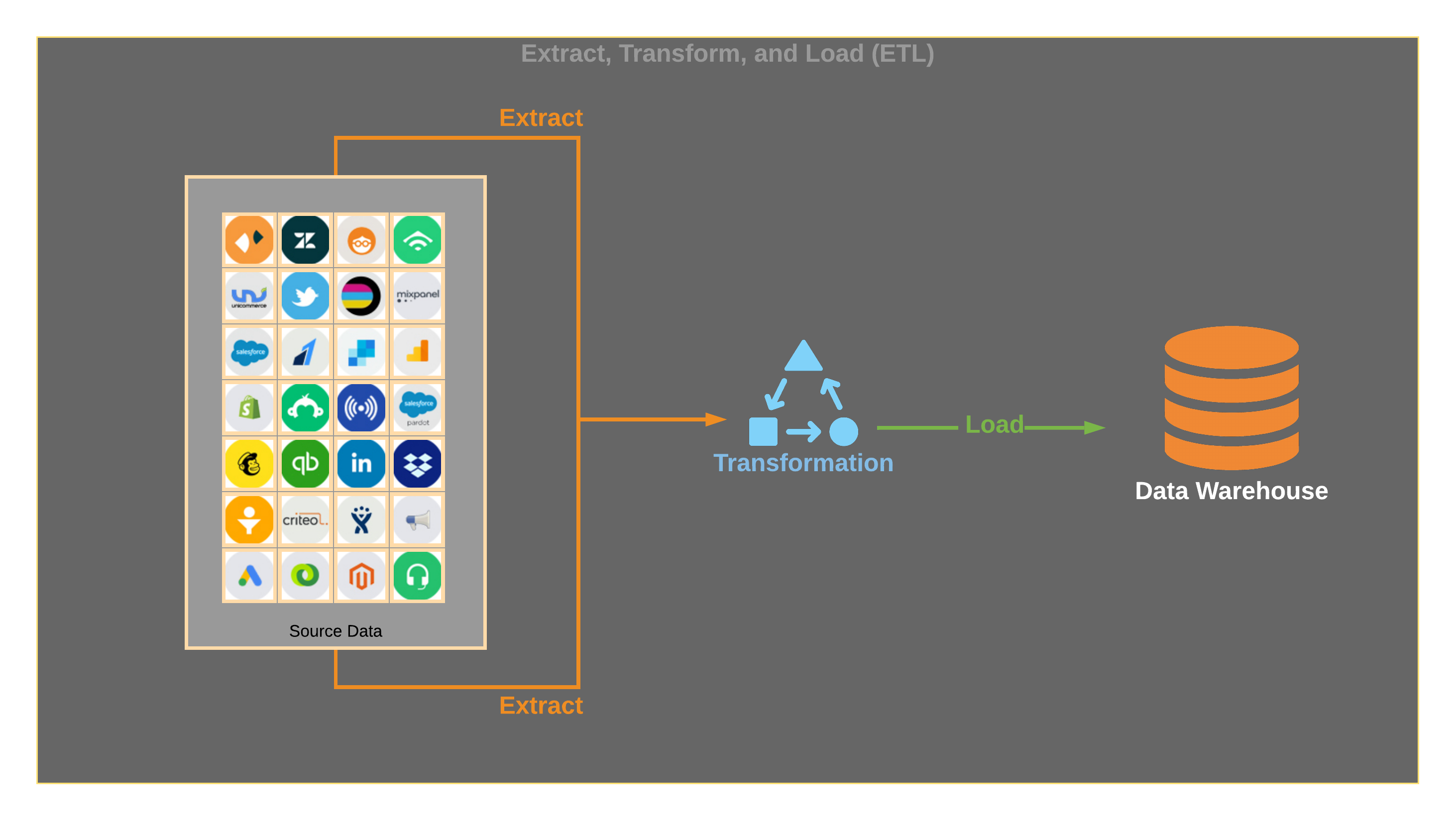
We believe that the right place to do extensive data transformations is in the data warehouse where the transformation functions can be written in SQL and can leverage the innovations in data warehousing technology to speed up the transformation process and to reduce costs. This formed the basis for our ELT approach where Daton acts more like an extract and load tool and relies on customers performing extensive transformations in the data warehouse.
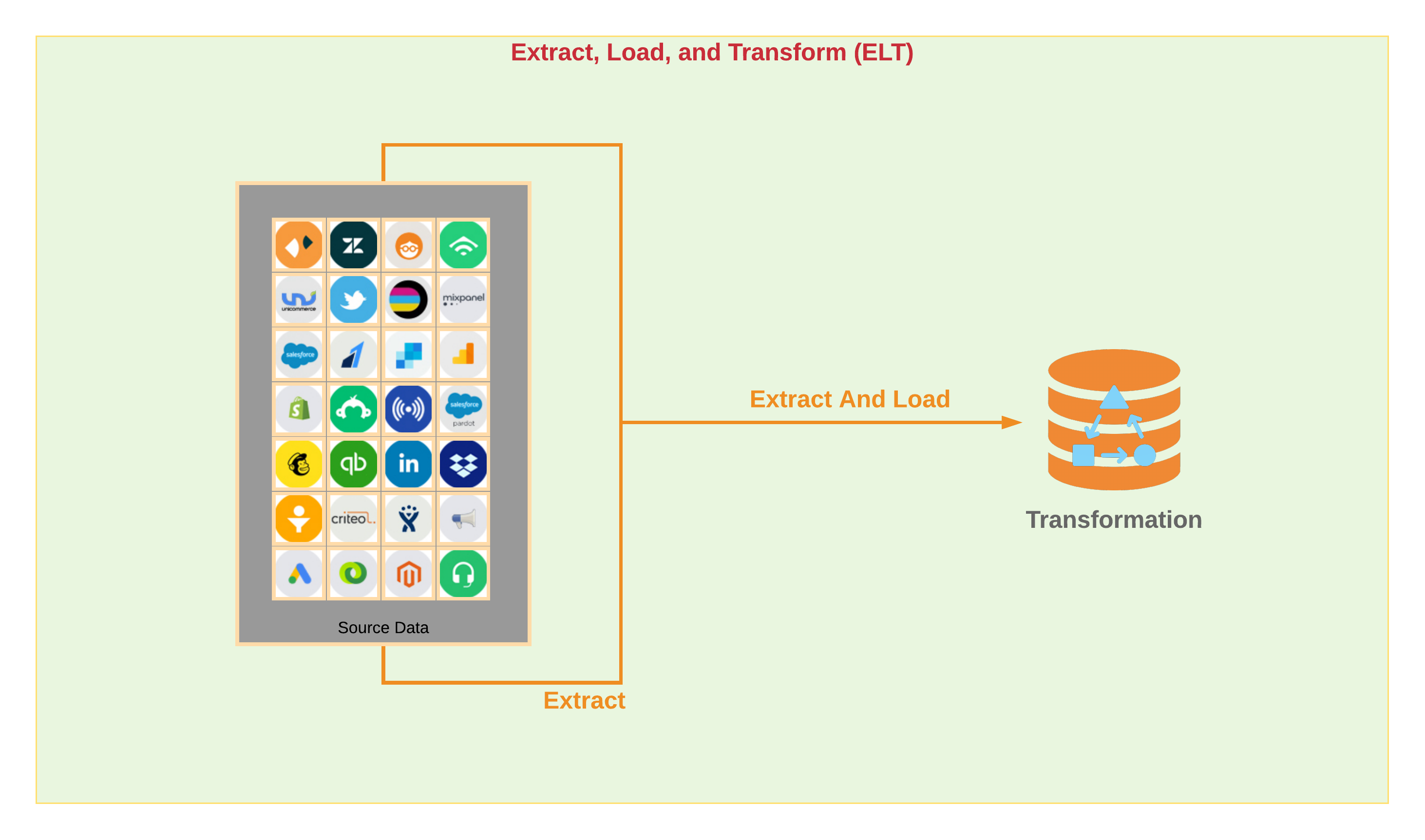
Daton Overview
A developer and analyst focused ELT service which allows you to configure data sources and build a new data warehouse or add new data sources to your existing data warehouse in a simple, efficient, and cost effective manner. Daton is a stress-free, fully-managed cloud data pipeline that allows business to have their key resources to focus on value creation instead of worrying about data engineering.
To unleash Daton, you will need the following:
- A Daton account
- Access to a data source
- Access to a data warehouse
Sources
Sources are the systems from which you would like Daton to extract data. Currently, we support many databases and applications like MySQL, Oracle DB, Postgres, Redshift , Google Analytics, Salesforce, and a lot more. We are constantly adding more data sources and you find a comprehensive list of supported sources here
Custom Source Development The number of applications that are currently in the market is immense and is growing at a rapid pace. If you find that a particular application that you are using is currently not supported by Daton, don't worry.
Please send us an email with the details of the application that you'd like added to Daton. We will add that integration for you at no additional cost. The turnaround time for the new integration development is based on your current subscription plan.
Replication
Replication is the process by which Daton extracts the data from the configured source systems and loads that data into a desired destination. To start replicating data between sources and destination, Daton leverages the source settings that the user selects through the configuration process. There are three key aspects to the replication settings.
In order for Daton to function, at least one source and a data warehouse has to be configured to create a replication job. Configuring a source integration in Daton is typically is a three step process.
- Step 1: Select the replication parameters
- Step 2: Select tables to replicate
- Step 3: Select fields to replicate
Step 1: Select the replication parameters
Integration Name: Integration name is the first of the replication parameters Daton uses to configure and start the replication jobs. An integration name is a unique identifier used for a specific source configuration in Daton. Daton uses the integration name to create tables in the data warehouse. In general, for REST API/SOAP API based applications and databases, Daton will append the integration name as a prefix to the table name before creating a table in the data warehouse, although there are exceptions to this process.
Here is a common example:
- Integration Name is Facebook_Ad
- Table name is campaigns
- The table name in the data warehouse will be Facebook_Ad_campaigns
There are cases where integration name contributes to the table name differently. Refer to this document for a more detailed breakdown of all scenarios and how table names are generated by Daton.
Please keep in mind that once an integration has been created, the integration name field can no longer be change.
Replication Frequency This parameter determines how frequently data gets extracted from the source system. They are two key terms in data replication that are important to understand. They are
-
Full data replication
- A full data replication or a full load is the first replication job that runs for any integration set up in Daton. This replication job, depending on the amount of data to be processed and the source system selected, could take anywhere between minutes to a few hours/days to run. There are many reasons why the first replication job could take a long time like
- Rate limits on source systems and
- Volume of data that has to be extracted
- A full data replication or a full load is the first replication job that runs for any integration set up in Daton. This replication job, depending on the amount of data to be processed and the source system selected, could take anywhere between minutes to a few hours/days to run. There are many reasons why the first replication job could take a long time like
Daton has been engineered to handle any system errors or outages a source system can encounter while the full load is in progress without any data loss.
-
Incremental data replication
- Once the initial data replication job is complete, Daton will run the subsequent replication jobs at a frequency that has been selected by the user. Currently, Daton supports a minimum frequency of one hour.
Screenshot highlights the integration setup screen that is common across a majority of sources.
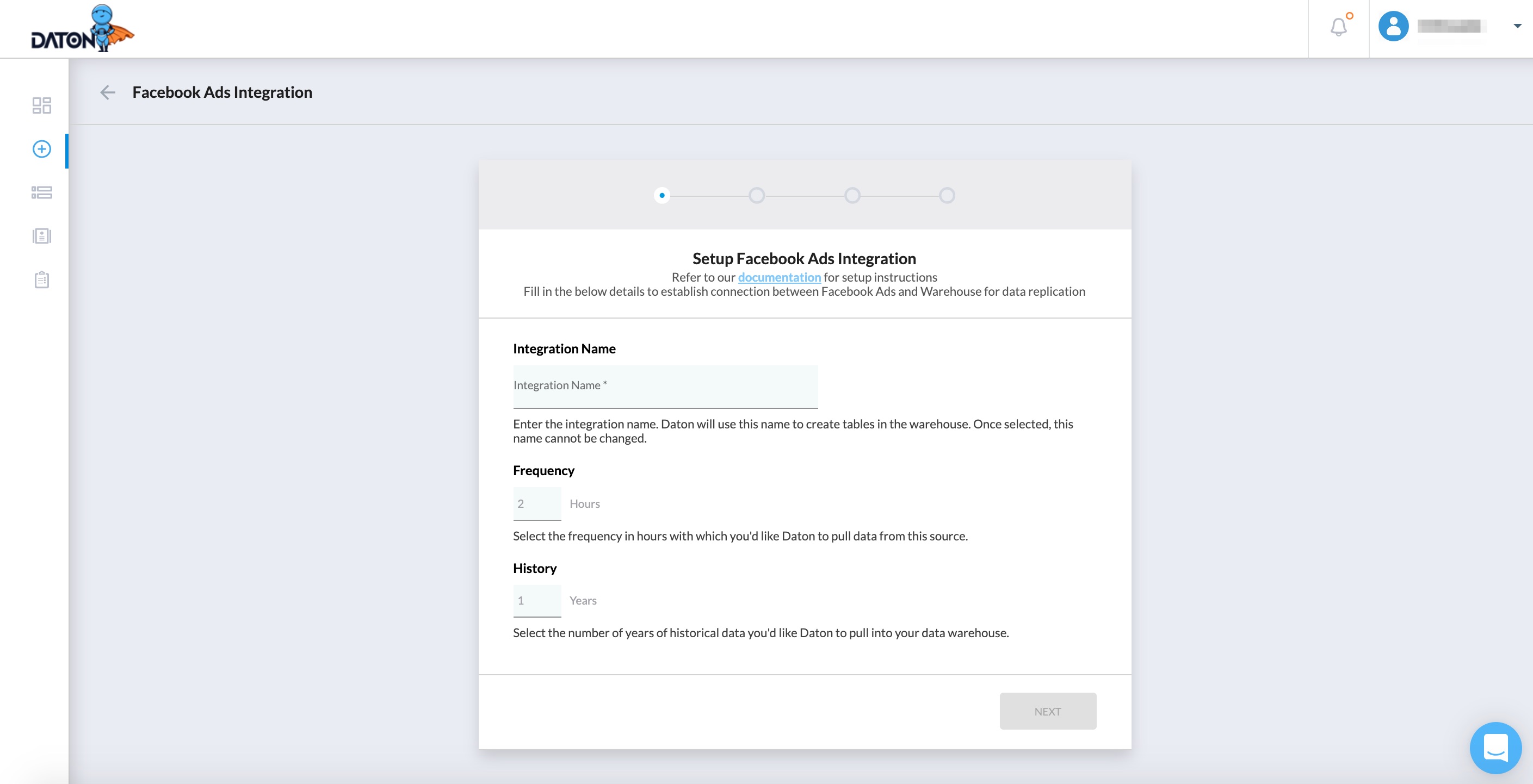
Historical Data This parameter determines how far back Daton has to go to extract data. You can go as far back as you'd like but we recommend that you use this parameter judiciously to ensure that you are only asking for data from the source system for the period that you know data exists. This parameter has a big influence on the time taken for the first full load to complete.
Step 2: Select tables to replicate
In most cases, only some of the data from the source system may be of interest from a reporting and analysis standpoint. Therefore, we built in the capability to allow users to select only the tables that they need from the source system for replication. Since Daton is charged based on the number of rows processed, this flexibility also helps in keeping the costs of Daton low.
The table names that you see on the screen, reflect part of the table name that you will find created in the data warehouse.
Here is a common example:
- Integration Name is Facebook_Ad
- Table name is campaigns
- The table name in the data warehouse will be Facebook_Ad_campaigns
Step 3: Select fields to replicate
Once you selected the tables to be replicated, the next screen allows you to choose the fields within these tables to be included in the replication job. Daton uses this selection to create columns for the tables in the data warehouse. The ability to select fields for replication is available only for data sources that permit extraction of data for a subset of table columns. In most cases, source systems allow selecting a subset of columns for replication. Where selection is not allowed, Daton skips this step and uses a standard set of fields for replication.
Types of Replication
Depending on the type of integration, Daton leverages different mechanisms to replicate data. In some cases, replication of incremental changes may be possible and in some cases it may not be possible. In order to handle these types of situations, Daton uses two different way to replicate data.
-
Full replication
- All the rows for tables that have been setup as full replication will be replicated every time a replication job for this source runs. Some sources allow extracting incremental data based on a timestamp of some unique identifier. Depending on the source, this mechanism may or may not be controlled. For example, you may using some SaaS application that provide RestAPIs to extract data from the source system. But, these APIs may not have pagination implemented yet. In such cases, there will be no way for Daton to identify the newly created rows and the entire table will be replicated. Please review the source documentation to understand how different sources behave.
- In order to keep Daton costs under check, please setup the integrations in such a way that full load on tables do not happen too frequently unless necessary.
-
Field based replication
- For database data sources, in addition to the fields selected for replication to a data warehouse, a replication field should also be selected. This replication field will be used by Daton to uniquely identify and process the records that have been modified after the most recent incremental or full data load.
- For example, if we use update_date as replication field, Daton will store the last update_date of the record from every replication job. Any records with a more recent update_date will be replicated to the destination.
- For SaaS applications, we have the responsibility of pre-determining the replication fields so that you don't have to. For applications that don't provide a replication field, full replication will be performed.
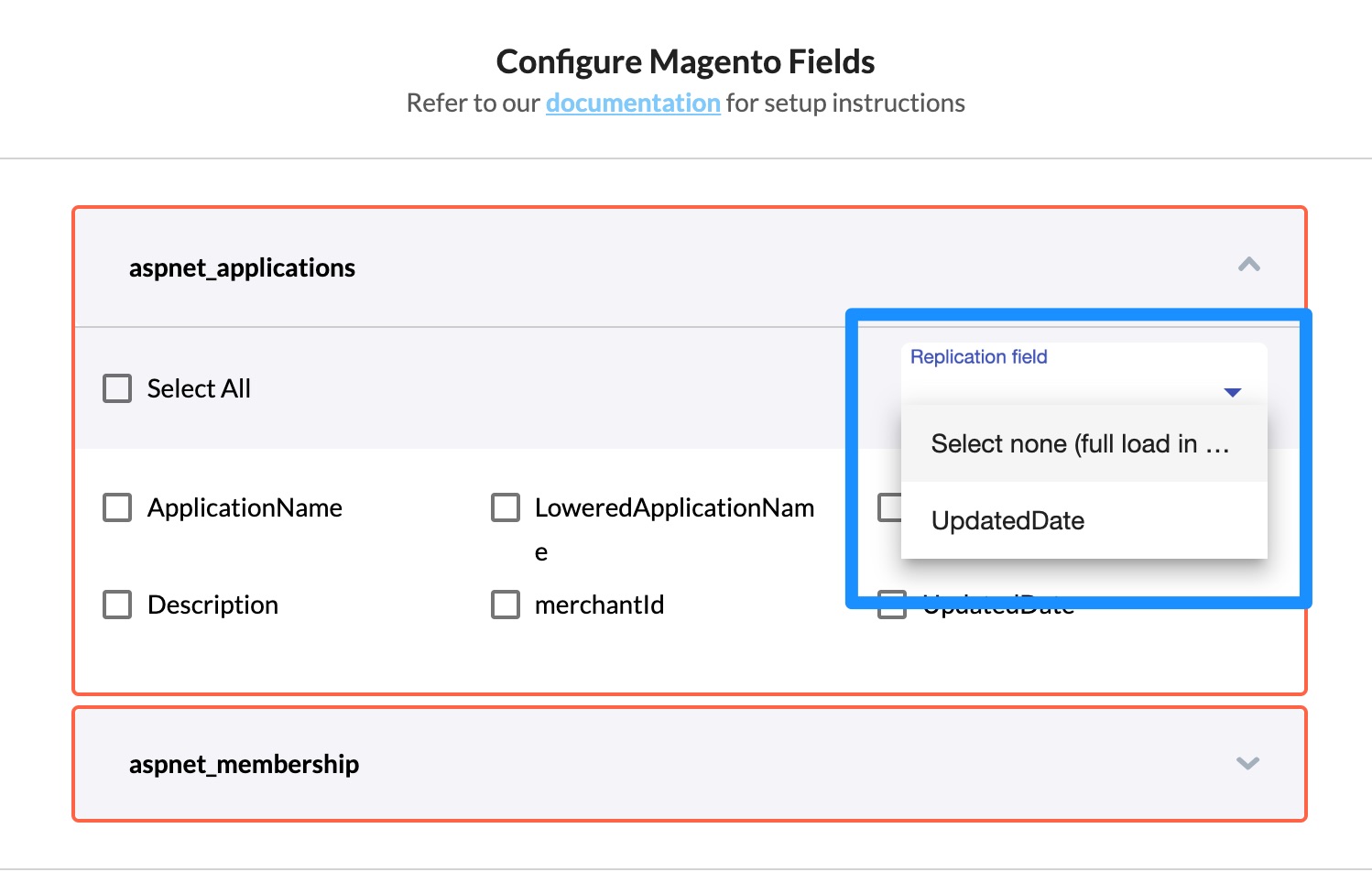
- For database data sources, in addition to the fields selected for replication to a data warehouse, a replication field should also be selected. This replication field will be used by Daton to uniquely identify and process the records that have been modified after the most recent incremental or full data load.
Destination
A destination for Daton is a cloud data warehouse or another database. There are many cloud data warehouses like Oracle Autonomous Data warehouse, Google BigQuery, AWS Redshift, Snowflake, and more in the market today. There are also a whole range of managed databases in the cloud like Oracle Database Cloud Service, AWS Aurora, Google Cloud SQL MySQL, and more that are supported by Daton as destinations. A comprehensive list of relational and non-relational data warehouses and databases that can be used as data warehouses are documented here.
At this point in time, Daton only supports loading data into one data warehouse per account. If you have requirements to use Daton for multiple data warehouses, please create another account.
Depending on the warehouse that the user is selecting, the workflow to create this data warehouse will change. A detailed documentation of how to create these data warehouses can be found at this link. To get you started, we will use Google BigQuery as example to highlight how easy it is to setup an end to end Data pipeline using Daton
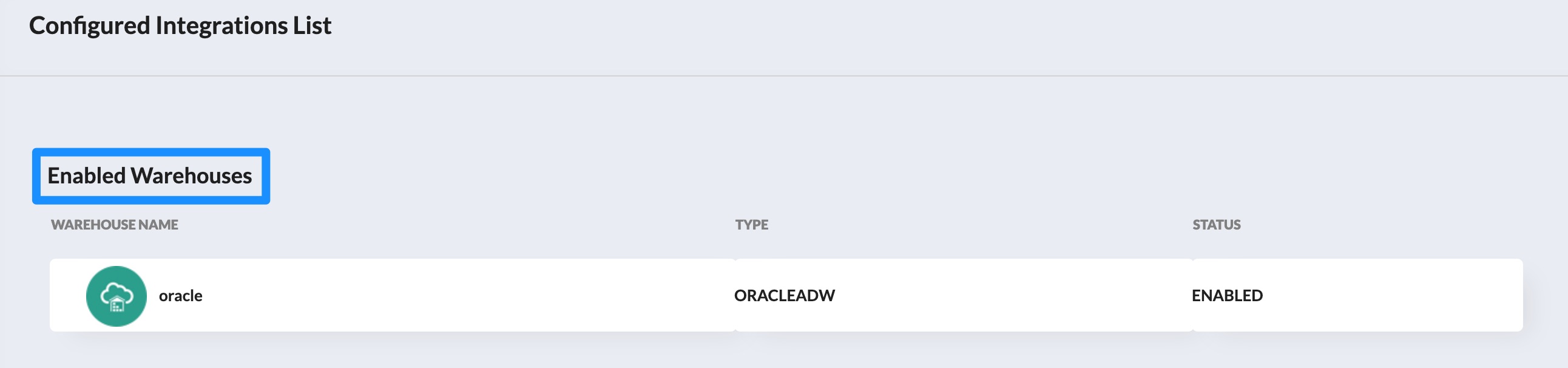
Deleting or Modifying a Data warehouse
Enabled Warehouse section in the Integrations tab on the menu to the left highlights the data warehouse that has been added to the account. Users can also modify the data warehouse settings and remove the data warehouse from the account.
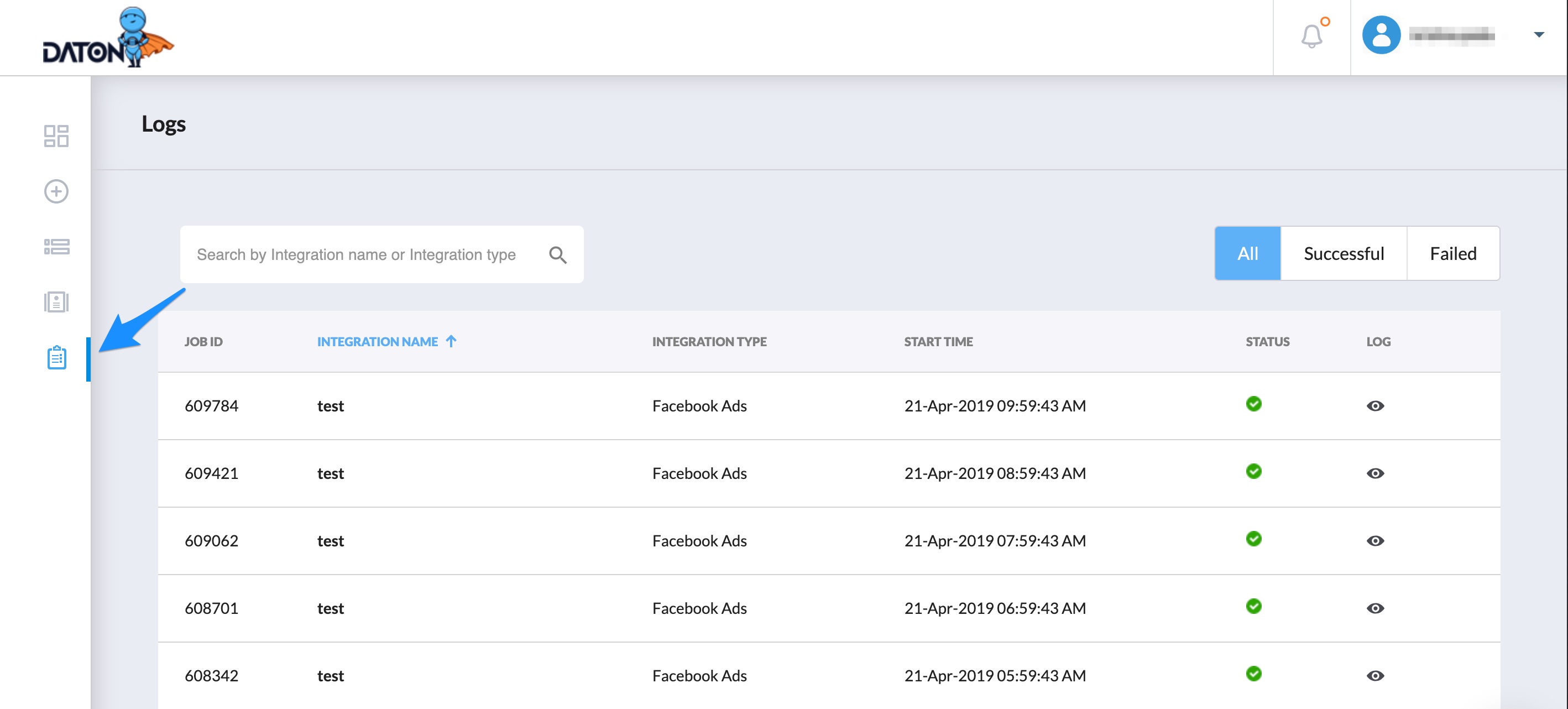
Pipeline Monitoring
All activity that is happening in the data pipeline is logged and is made available to the user through the user interface. Pipeline job logs are available for a set period of time based on the choice of subscription. Older logs are removed from the system and will not be available outside the duration specified in the subscription plan.
Support
If you have any questions regarding Daton or having any difficulty using the product, do not hesitate to reach out to us. Our support team is available for you on multiple mediums. You can
- Email us at support@sarasanalytics.com
- Chat with us using the intercom window in the application.
If you would like to get a demo of Daton, please send us a note at support@sarasanalytics.com.
We strive to make our documentation as clear and legible as possible. But, if you feel there are discrepancies or areas of improvement for us, please send us a note.